《编写高质量代码-改善Python程序的91个建议》读书笔记
语言类型:Python
来源: Kindle
书名: 《编写高质量代码-改善Python程序的91个建议》
记录一些没有理解到位的知识点
使用文件存储常量
1 | class _const: |
理解枚举替代实现的缺陷
参考 Enum
备注: 目前还没有合适的场景使用枚举, 待有需要时加以学习
尽量转换为浮点型后在进行除法运算
该内容适用于Python2,
对现代Python3无需特殊转义
1 | gpa = ((4 * 96 + 3 * 85 + 5 * 98 + 2 * 70) * 4) / ((4 + 3 + 5 + 2) * 100) |
分清is和==的适用场景
==操作符可以被重载, 而is不能被重载
is用于判断两个对象的id是否相同, 返回较快,
不会调用两个对象的__eq__方法进行计算
==会调用__eq__方法计算两个对象是否相等
使用else子句简化循环处理(异常处理)
当循环“自然”终结(循环条件为假)时else从句会被执行一次,而当循环是由break语句中断时,else子句就不被执行。
与for语句相似,while语句中的else子句的语意是一样的:else块在循环正常结束和循环条件不成立时被执行。
在循环中的else表示循环正常中断,即抛出StopIteration Exception时执行else的代码块,该特性可以简化逻辑
避免finally中可能发生的陷阱
注意finally无论是否有异常抛出/循环终止与否, 都会默认执行, 如果在finally的代码块中执行了返回操作, 那么上面的所有返回都会被忽略
格式化字符串时尽量使用.format方式而不是%
format支持多种形式的格式化:
位置符号
1
2
3"The number {0:,} in hex is: {0:#x}, the number {1} in oct is {1:#o}".format(4746,45)
'The number 4,746 in hex is: 0x128a, the number 45 in oct is 0o55'
# 其中{0}表示format方法中对应的第一个参数,{1}表示format方法对应的第二个参数,依次递推名称
1
2print "the max number is {max}, the min number is {min}, the average number is {average:0.3f}".format(max=189,min=12.6,average=23.5)
the max number is 189, the min number is 12.6, the average number is 23.5003通过属性
1
2
3
4
5
6
7
8
9
10
11class Customer(object):
def __init__(self, name, gender, phone):
self.name = name
self.gender = gender
self.phone = phone
def __str__(self):
return 'Customer({self.name},{self.gender},{self.phone})'.format(self=self) # 通过str()函数返回格式化的结果...
str(Customer("Lisa","Female","67889"))
'Customer(Lisa,Female,67889)'元组
1
2
3point=(1,3)
'X:{0[0]};Y:{0[1]}'.format(point)
'X:1;Y:3'
Python函数参数传递的是对象的引用(call by object reference)
因此函数的参数需要注意, 因为是对对象的引用进行传递, 因此是在内外都可见的. 如果修改了可变对象的值, 那么会导致外部对象的改变
慎用变长参数
1 | def set_axis(x,y,xlabel="x",ylabel="y",*args,**kwargs): |
上面的所有调用方式都是合法的!
实际上在4种不同形式的参数同时存在的情况下,会首先满足普通参数,然后是默认参数。
如果剩余的参数个数能够覆盖所有的默认参数,则默认参数会使用传递时候的值,如标注①处的函数在调用的时候xlabel和ylabel的值分别为“test1”和“test2”;
如果剩余参数个数不够,则尽最大可能满足默认参数的值,标注②中xlabel值为“test1”,而ylabel则使用默认参数y。
除此之外其余的参数除了键值对以外所有的参数都将作为args的可变参数,kwargs则与键值对对应。
因此会带来问题:
- 使用过于灵活, 导致函数签名不清晰, 调用者需要花费过多时间研究如何调用, 且会破坏程序的健壮性
- 如果函数参数列表很长, 表名该函数应该存在更好的实现方式, 应该被重构
- 变长参数一般用于创建装饰器, 或者参数数目不确定, 或者子类继承父类等
深入理解str()和repr()的区别
两者之间的目标不同:
str()主要面向用户,其目的是可读性,返回形式为用户友好性和可读性都较强的字符串类型;
而repr()面向的是Python解释器,或者说开发人员,其目的是准确性,其返回值表示Python解释器内部的含义,常作为编程人员debug用途
在解释器中直接输入a时默认调用repr()函数,而print a则调用str()函数。
repr()的返回值一般可以用eval()函数来还原对象,通常来说有如下等式。
obj == eval(repr(obj))这两个方法分别调用内建的
__str__()和__repr__()方法,一般来说在类中都应该定义__repr__()方法,而__str__()方法则为可选,当可读性比准确性更为重要的时候应该考虑定义__str__()方法。如果类中没有定义
__str__()方法,则默认会使用__repr__()方法的结果来返回对象的字符串表示形式。用户实现__repr__()方法的时候最好保证其返回值可以用eval()方法使对象重新还原。
分清classmethod和staticmethod的适用场景
主要区别:
- classmethod表示该方法对该类强相关, 在子类继承的时候会自动为子类生成类变量, 如果存在多个子类继承, 使用静态方法会导致变量值异常
- staticmethod既不跟特定的实例相关也不跟特定的类相关, 静态方法定义在类中,较之外部函数,能够更加有效地将代码组织起来,从而使相关代码的垂直距离更近,提高代码的可维护性
使用Counter来实现计数功能
1 | from collections import Counter |
Counter会自动计算所有字符和字符出现的次数, 并且支持其他类自然语言的方法调用
深入理解ConfigParser
getboolean()函数可以将各种贴近自然语言的值转义为True/False,
除了0之外,no、false和off都会被转义为False,而对应的1、yes、true和on则都被转义为True,其他值都会导致抛出ValueError异常。这样的设计非常贴心,使得我们能够在不同的场合使用yes/no、true/false、on/off等更切合自然语言语法的词汇,提升配置文件的可维护性。
DEFAULT节可以为配置项指定默认参数,
如在某个section无法查找到指定配置, 则使用DEFAULT节中配置的缺省值
使用traceback获取栈信息
可以通过命令traceback.print_exc()打印产生异常的相关文件和对应的调用顺序错误类型等信息
使用mixin模式让程序更加灵活
1 | def simple_tea_people(): |
这个代码能够运行的原理是,每个类都有一个__bases__属性,它是一个元组,用来存放所有的基类。
与其他静态语言不同,Python语言中的基类在运行中可以动态改变。所以当我们向其中增加新的基类时,这个类就拥有了新的方法,也就是所谓的混入(mixin)。
这种动态性的好处在于代码获得了更丰富的扩展功能。想象一下,你之前写好的代码并不需要个性,只要后期为它增加基类,就能够增强功能(或替换原有行为),这多么方便!值得进一步探索的是,利用反射技术,甚至不需要修改代码。
使用发布订阅模式实现松耦合
1 | import message |
可以将原有功能或者未添加日志输出等函数, 通过发布订阅模式输出日志, 从而不修改原有函数依赖包或者相关参数
因为pythonmessage的消息订阅默认是全局性的,所以有可能产生名字冲突。
在减少名字冲突方面,可以借鉴java/actionscript3的package起名策略,比如在应用中定义消息主题常量FOO='com.googlecode.pythonmessage.FOO',这样多个库同时定义FOO常量也不容易冲突。除此之外,还有一招就是使用uuid
用状态模式美化代码
1 | from state import curr, switch, stateful, State, behavior |
某些地方,你除了要确定登录之外,还需要确定是否在战斗副本中,角色是否已经死亡……等等。想象一下,十个八个方法,每个方法上面都顶着四五个修饰函数,该有多么丑陋!这就是状态模式可以美化的地方。
1 | class User(object): |
可以看到,当用户登录以后,就切换到了Player.Signin状态,而在Signin状态的行为是不需要做是否已经登录的判断的,这是因为除了登录成功,User的实例无法跳转到Signin状态,反过来说就是只要当前状态是Signin,那必定已经登录,自然无须再验证。
可以看到,通过状态模式,可以像decorator一样去掉if…raise…上下文判断,但比它更棒的是真的一个if…raise…都没有了。
另外,需要多重判断的时候要给一个方法戴上四五顶“帽子”的情况也没有了,还通过把多个方法分派到不同的状态类,消灭掉一般情况下Player总是一个巨类的“坏味道”,保持类的短小,更容易维护和重用。
不过这些都比不上一个更大的好处:当调用当前状态不存在的行为时,出错信息抛出的是AttributeError,从而避免把问题变为复杂的逻辑错误,让程序员更容易找到出错位置,进而修正问题。
理解__init__()并不是构造方法
实际上__init__()并不是真正意义上的构造方法,__init__()方法所做的工作是在类的对象创建好之后进行变量的初始化。__new__()方法才会真正创建实例,是类的构造方法。
1 | class A(object): |
- new()方法一般需要返回类的对象,当返回类的对象时将会自动调用__init__()方法进行初始化,如果没有对象返回,则__init__()方法不会被调用。init()方法不需要显式返回,默认为None,否则会在运行时抛出TypeError。
- 当需要控制实例创建的时候可使用__new__()方法,而控制实例初始化的时候使用__init__()方法。
- 一般情况下不需要覆盖__new__()方法,但当子类继承自不可变类型,如str、int、unicode或者tuple的时候,往往需要覆盖该方法。
- 当需要覆盖__new__()和__init__()方法的时候这两个方法的参数必须保持一致,如果不一致将导致异常。
理解名字查找机制
Python中的作用域自Python2.2之后分为:
局部作用域(local)
全局作用域(Global)
嵌套作用域(enclosingfunctionslocals)
嵌套作用域不能通过
global修改上层函数值1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def inner():
global a
a = 'Inner a value'
print(a)
def outter():
a = 'Outer a value'
print(a)
inner()
print(a)
# 输出结果
# Outer a value
# Inner a value
# Outer a value
# 可以看出, 内部函数嵌套不能通过global修改外层的值内置作用域(Buildin)
Python的名字查找机制: 其查找顺序遵循变量解析机制LEGB法则,即依次搜索4个作用域:局部作用域、嵌套作用域、全局作用域以及内置作用域,并在第一个找到的地方停止搜寻,如果没有搜到,则会抛出异常。
理解MRO与多继承
1 | class A: |
详细信息参见: Python MRO方法解析顺序详解
理解描述符机制
当通过“.”操作符访问时,Python的名字查找并不是之前说的先在实例属性中查找,然后再在类属性中查找那么简单,实际上,根据通过实例访问属性和根据类访问属性的不同,有以下两种情况:
- 一种是通过实例访问,比如代码obj.x,如果x是一个描述符,那么
__getattribute__()会返回type(obj).__dict__['x'].__get__(obj,type(obj))结果,即:type(obj)获取obj的类型;type(obj).__dict__['x']返回的是一个描述符,这里有一个试探和判断的过程;最后调用这个描述符的__get__()方法。 - 另一种是通过类访问的情况,比如代码cls.x,则会被
__getattribute__()转换为cls.__dict__['x'].__get__(None,cls)。
附property具体实现
1 | class Property(object): |
区别__getattr__()和__getattribute__()方法
__getattr__()方法仅如下情况下才被调用:
- 属性不在实例的__dict__中;属性不在其基类以及祖先类的
__dict__中; - 触发AttributeError异常时(注意,不仅仅是
__getattribute__()引发的AttributeError异常,property中定义的get()方法抛出异常的时候也会调用该方法)。
覆盖__getattr__()方法时需要注意:
- 避免无穷递归.
可以通过
super(obj,self).__getattribute__(attr)实现避免无穷递归 - 访问未定义的属性时, 可能导致与预期不符.
如果在
__getattr()__方法中不抛出AttritubeError异常或者显示返回一个值, 那么默认会返回None作为属性的返回值, 导致与预期不符.
核心结论:
__getattribute__()总会被调用,而__getattr__()只有在__getattribute__()中引发异常的情况下才会被调用。
使用更为安全的property
property的优势:
- 代码更加简洁, 可读性更强
- 更好的管理属性的访问
- 代码可维护性更好
- 控制属性访问权限, 提高数据安全性
掌握metaclass
metaclass暂时翻译为元类, 定义:
- 元类是关于类的类,是类的模板。
- 元类是用来控制如何创建类的,正如类是创建对象的模板一样。
- 元类的实例为类,正如类的实例为对象。
type实际上是Python的一个内建元类,用来直接指导类的生成。默认情况下,
用户定义的类的元类都是type
Python界的领袖TimPeters曾这样说过:“元类就是深度的魔法,99%的用户应该根本不必为此操心。如果你想搞清楚究竟是否需要用到元类,那么你就不需要它。那些实际用到元类的人都非常清楚地知道他们需要做什么,而且根本不需要解释为什么要用元类。”
元类使用的注意点:
区别类方法和元方法(定义在元类中的方法).
元方法可以从元类或者类中调用,而不能从类的实例中调用;但类方法可以从类中调用,也可以从类的实例中调用。
多继承需要严格限制, 否则会产生冲突.
类似于类的菱形继承
熟悉Python对象协议
用于比较大小的协议:
主要依赖
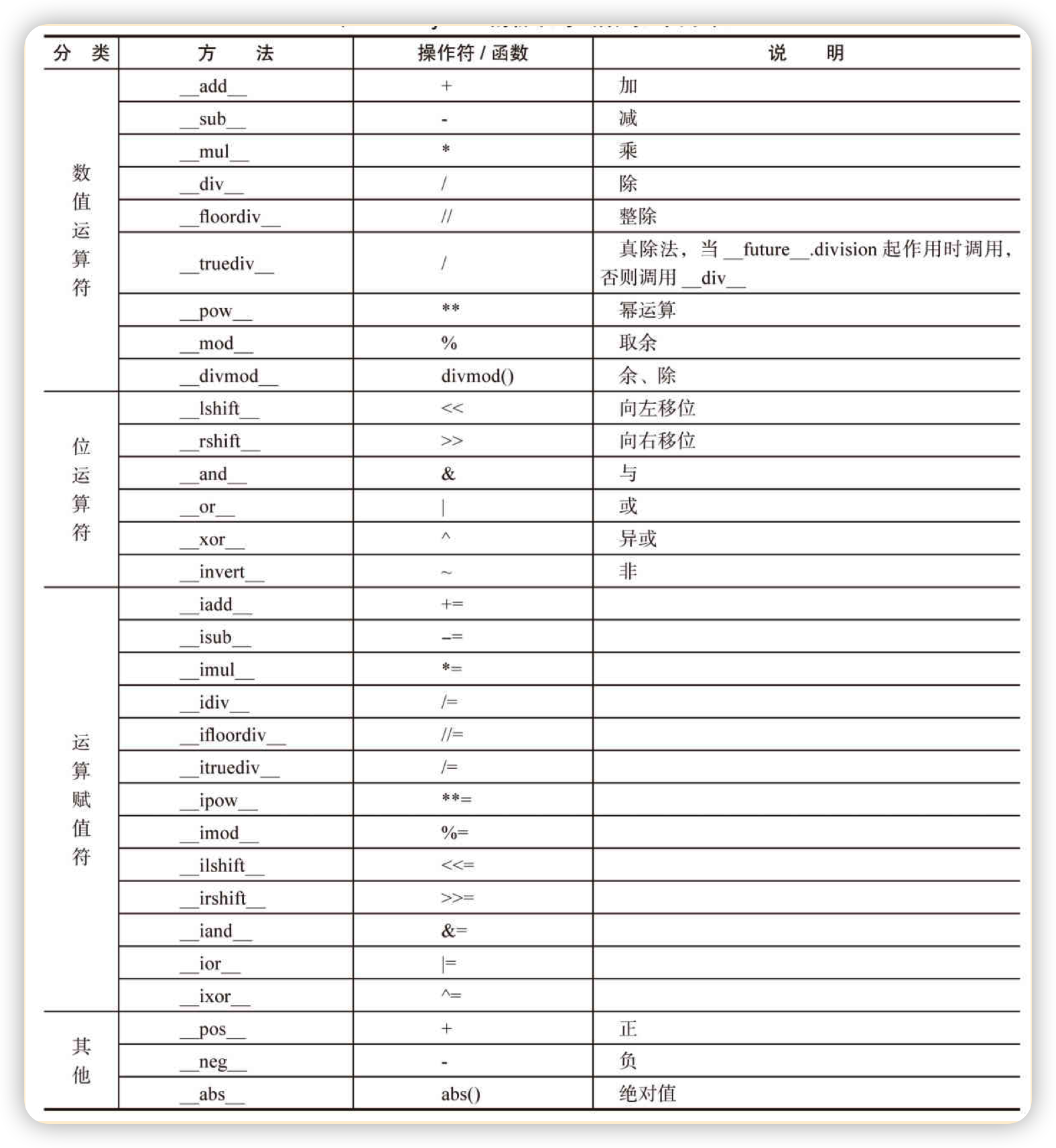
__cmp__()方法, Python通过使用__eq__()/__ne__()/__lt__()/__gt__()等魔术方法实现对==/!=/</>等操作符的重载魔术方法 对应操作符 描述 __eq__() == equal缩写, 用于判断是否相等 __ne__() != not equal缩写, 用于判断是否不等 __lt__() < less than缩写, 用于判断是否小于 __gt__() > greater than缩写, 用于判断是否大于 __le__() <= less equal缩写, 用于判断是否小于等于 __ge__() >= greater equal缩写, 用于判断是否大于等于 数值类型相关协议: 如下图
Python中独有的概念:
反运算, 如执行A+B操作, 如果A类中未定义__add__()方法, 那么就会去B方法中查找名为__radd__()的方法, 通过调用B.__radd__()方法, 实现A+B运算, 其他规则类似.
容器类型协议
内置函数 魔法方法 说明 len() __len__() 返回对象长度 OBJ[Key] __getitem__() 获取字典类型值 OBJ[Key] = abc __setitem__() 修改字典类型值 del __delitem__() 删除字典类型值 iter() __iter__() 迭代方法 reversed() __reversed__() 翻转方法 In / not in __contains__() 是否包含方法 在Python中,就是要支持内置函数len(),通过__len__()来完成,一目了然。而__getitem__()、setitem()、delitem()则对应读、写和删除,也很好理解。iter()实现了迭代器协议,而__reversed__()则提供对内置函数reversed()的支持。容器类型中最有特色的是对成员关系的判断符in和notin的支持,这个方法叫__contains__(),只要支持这个函数就能够使用in和notin运算符了。
可调用对象协议
就是实现了__call__()魔法方法的类, 调用的时候默认会执行魔术方法中的内容
可哈希对象协议
就是实现了__hash__()魔法方法的类, 新式类默认支持
上下文管理器协议
通过__enter__()和__exit__()两个方法来实现对资源的清理,确保资源无论在什么情况下都会正常清理。
利用操作符重载符实现中缀语法
管道的处理非常清晰,因为它是中缀语法。而我们常用的Python是前缀语法的,比如类似的Python代码应该是sort(ls(),reverse=True),明显没有那么清晰,特别是在极限情况下。
pipe库重载了__ror__()方法, 以实现中缀语法, 如下
1 | fib()|take_while(lambda x: x < 1000000)|where(lambda x: x % 2)|select(lambda x: x * x)|sum() |
找出小于1000000的斐波那契数,并计算其中的偶数的平方之和。
熟悉Python的迭代器协议
迭代器实现的两个要点
- 实现__iter__()方法,返回一个迭代器。
- 实现next()方法,返回当前的元素,并指向下一个元素的位置,如果当前位置已无元素,则抛出StopIteration异常。
迭代器最大的好处是定义了统一的访问容器(或集合)的统一接口,所以程序员可以随时定义自己的迭代器,只要实现了迭代器协议就可以。
除此之外,迭代器还有惰性求值的特性,它仅可以在迭代至当前元素时才计算(或读取)该元素的值,在此之前可以不存在,在此之后可以销毁,也就是说不需要在遍历之前事先准备好整个迭代过程中的所有元素,所以非常适合遍历无穷个元素的集合(如斐波那契数列)或巨大的事物(如文件)。
itertools
最为人所熟知的版本,应该算是zip、map、filter、slice的替代,izip(izip_longest)、imap(startmap)、ifilter(ifilterfalse)、islice,它们与原来的那几个内置函数有一样的功能,只是返回的是迭代器(在Python3中,新的函数撤底替换掉了旧函数)。
除了对标准函数的替代,itertools还提供以下几个有用的函数:
chain()用以同时连续地迭代多个序列
compress()、dropwhile()和takewhile()能用以遴选序列元素
tee()就像同名的UNIX应用程序,对序列作n次迭代
groupby的效果类似SQL中相同拼写的关键字所带的效果。
1
2[k for k, g in groupby('AAAABBBCCDAABBB')] > ABCDAB
[list(g) for k, g in groupby('AAAABBBCCD')] > AAAABBBCCD除了这些针对有限元素的迭代帮助函数之外,还有count()、cycle()、repeat()等函数产生无穷序列,这3个函数就分别可以产生算术递增数列、无限重复实参序列的序列和重复产生同一个值的序列。

熟悉Python的生成器
生成器,顾名思义,就是按一定的算法生成一个序列,比如产生自然数序列、斐波那契数列等。
之前讲迭代器的时候,就讲过一个生成波那契数列的例子。那么迭代器也是生成器?
其实不然。迭代器虽然在某些场景表现得像生成器,但它绝非生成器;反而是生成器实现了迭代器协议的,可以在一定程度上看作迭代器。
1 | def fib(n): |
可以看到它返回的是一个generator类型的对象,而这个对象带有__iter__()和next()方法,可见的确是一个迭代器。但那些next()、send()、throw()、close()等方法是怎么回事?
直率地说,send()方法很绕,这不是一个好名字。其实send()是全功能版本的next(),或者说next()是send()的“快捷方式”,相当于send(None)。还记得yield表达式有一个“返回值”吗?send()方法的作用就是控制这个返回值,使得yield表达式的“返回值”是它的实参。
除了能yield表达式的“返回值”之外,也可以让它抛出异常,这就是throw()方法的能力。
当调用close()方法时,yield表达式就抛出GeneratorExit异常,生成器对象会自行处理这个异常。当调用close()之后,再次调用next()、send()会使生成器对象抛出StopIteration异常,换言之,这个生成器对象已经不可再用。最后值得一提的是,当生成器对象被GC回收时,会自动调用close()。
生成器可以用于实现with语句的上下文管理器协议,利用的是调用生成器函数时函数体并不执行,当第一次调用next()方法时才开始执行,并执行到yield表达式后中止,直到下一次调用next()方法这个特性, 但是实现上下文管理器协议需要实现__enter__()方法和__exit__()方法, 生成器对象并没有实现这两种方法, contextlib提供了contextmanager函数来适配这两种协议。通过contextmanager对next()、throw()、close()的封装,yield大大简化了上下文管理器的编程复杂度,对提高代码可维护性有着极大的意义。
熟悉Python携程的实现Greenlet
1 | from greenlet import greenlet |
最后一行跳到test1,输出12,跳到test2,输出56,跳回test1,输出34;然后test1执行完,gr1就死了。然后,最初的gr1.switch()调用返回,所以永远也不会输出78。
协程虽然不能充分利用多核,但它跟异步I/O结合起来以后编写I/O密集型应用非常容易,能够在同步的代码表面下实现异步的执行,其中的代表当属将greenlet与libevent/libev结合起来的gevent程序库,它是当下最受欢迎的Python网络编程库。
1 | import gevent |
理解GIL的局限性
GIL被称为为全局解释器锁(GlobalInterpreterLock),是Python虚拟机上用作互斥线程的一种机制,它的作用是保证任何情况下虚拟机中只会有一个线程被运行,而其他线程都处于等待GIL锁被释放的状态。
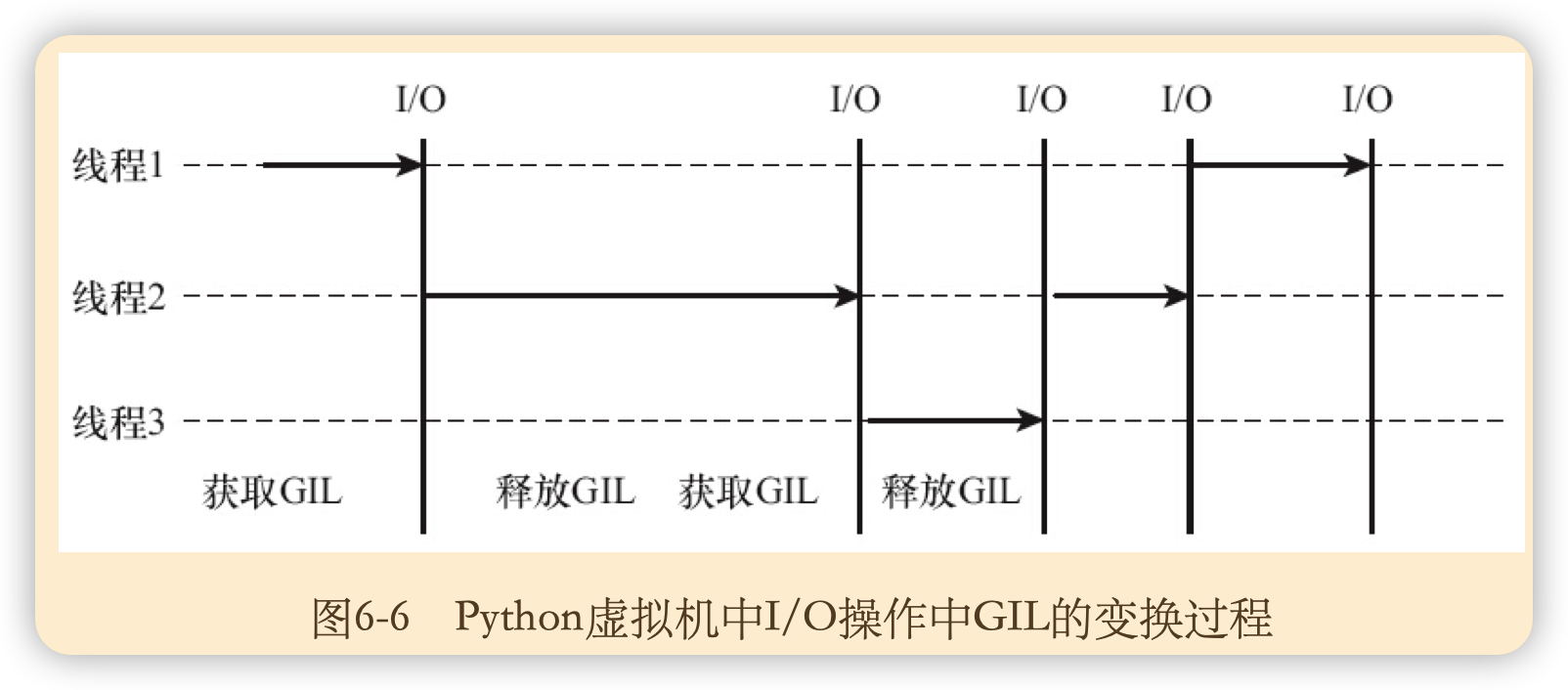
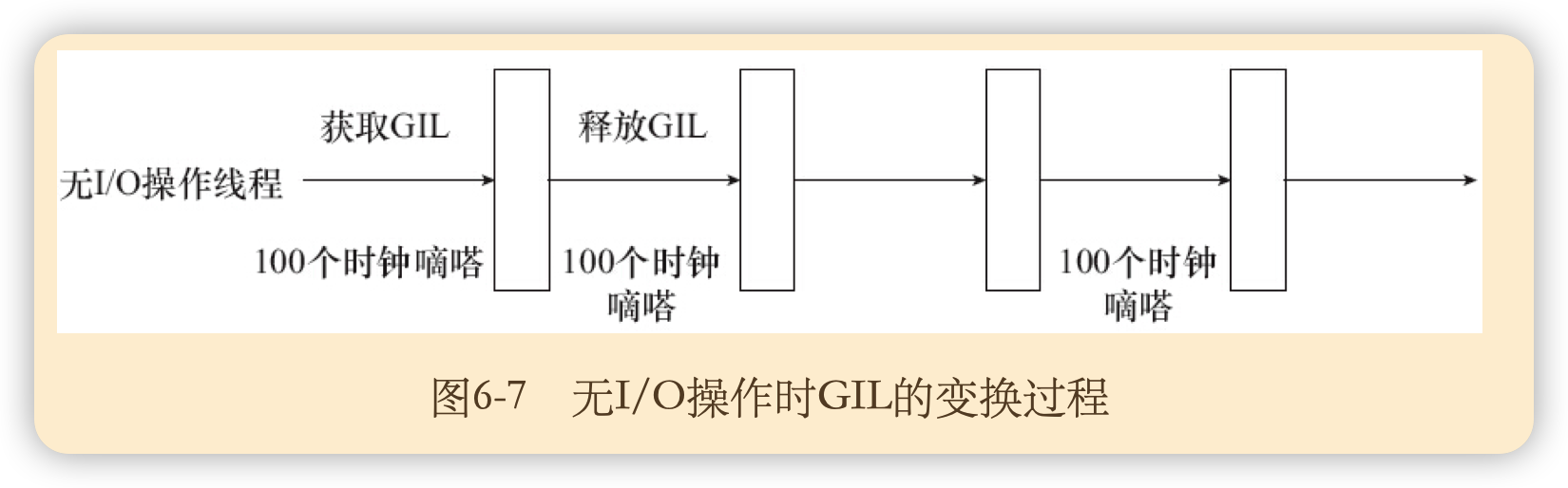
GIL的引入确实使得多线程不能在多核系统中发挥优势,但它也带来了一些好处:
- 大大简化了Python线程中共享资源的管理,在单核CPU上,由于其本质是顺序执行的,一般情况下多线程能够获得较好的性能。
- 此外,对于扩展的C程序的外部调用,即使其不是线程安全的,但由于GIL的存在,线程会阻塞直到外部调用函数返回,线程安全不再是一个问题。
对象的管理与垃圾回收
Python使用引用计数器(Referencecounting)的方法来管理内存中的对象,即针对每一个对象维护一个引用计数值来表示该对象当前有多少个引用。
当其他对象引用该对象时,其引用计数会增加1,而删除一个对当前对象的引用,其引用计数会减1。
只有当引用计数的值为0的时候该对象才会被垃圾收集器回收,因为它表示这个对象不再被其他对象引用,是个不可达对象。
引用计数算法最明显的缺点是无法解决循环引用的问题,即两个对象相互引用。
当存在循环引用并且当这个环中存在多个析构方法时,垃圾回收器不能确定对象析构的顺序,所以为了安全起见仍然保持这些对象不被销毁。而当环被打破时,gc在回收对象的时候便会再次自动调用__del__()方法。